Data Videos
#Data -AWS re:Invent 2017 - Announcing AWS DeepLens
Let's say that a company wants to know when new tables are added to a JDBC source (say, an RDBMS). Using the ListDatabaseTables processor, we can get a list of TABLE s, and also views, system tables, and other database objects, but for our purposes, we want tables with data. I have used the ngdbc.jar from SAP HANA to connect and query tables with ease.
For today's example, I am connecting to MySQL, as I have a MySQL database available for use and modification.
Imagine finding a DBMS that aligns with tech goals of your organization. Pretty exciting, right?
Relational databases held the lead for quite a time. Choices were quite obvious: MySQL, Oracle or MS SQL, to mention a few. Though times have changed pretty much with the demand for more diversity and scalability, haven't they?
Speedment is an open-source implementation of the Stream interface that lazily evaluates the operations performed on it to produce an optimal SQL query, fetching only the results needed for the terminating operation. Speedment also comes with a handy Maven plugin that generates all the entity and manager classes needed to model the database using the database metadata as the domain. This means that you can get a database application up-and-running in no time.
JShell Queries in Java 9In this video, Per Minborg and I demonstrate the database streams using JShell, the new REPL loop that comes with Java 9. We also explain how the Speedment implementation can optimize the streams before execution and why this is legal according to the Stream documentation. At the end of the video you have all the tools you need to quickly write Java 9-ready database applications using Streams instead of SQL.
Just the other day, I had a conversation with an Investment Risk Manager about one of the data problems his team was working on and he was wondering if Neo4j could help. Imagine you have about 20,000 mutual funds and ETFs, and you want to track how they measure up against a benchmark like, say, the returns of the S&P 500. I’m sorry, did I say one? I meant all of them — let’s say, 2,000 different benchmarks — and you want to track it every day for a rolling five-year period. So, that’s 20,000 securities * 2000 benchmarks * 5 years * 252 trading days a year (on average)… or... 50 billion data points. That’s a big join table if we're using a relational database. How can we efficiently model this in Neo4j?
To keep things simple, let’s say we only want to track one measure, and that measure is R-squared. When we compare the change in the value of the mutual fund vs. the benchmark, how closely did the changes track? R-squared is always between 0 and 1. A value of zero means the benchmark has nothing to do with the mutual fund, and a value of one means it has everything to do with it. So how could we model this?
In this article, we will review the basics of how to use Redis with Spring Boot through the Spring Data Redis library.
We will build an application that demonstrates how to perform CRUD operations Redis through a web interface. The full source code for this project is available on GitHub.
In this blog, we will learn about Lagom persistence with the help of a simple application. We'll also discuss its theoretical aspects.
Before we begin, make sure you know about event sourcing and CQRS. You can read about them in more detail here.
The preferred method for modifying your data within a database is T-SQL. While the last Fundamentals post showed how to use the GUI to get that done, it’s not a very efficient mechanism. T-SQL is efficient.
UPDATEThe command for updating information in your tables is UPDATE. This command doesn’t work the same way as the INSERT statement. Instead of listing all the columns that are required — meaning columns that don’t allow for NULL values — you can pick and choose the individual columns that you want to update. The operation over-writes the information that was stored in the column with new information. In addition to defining the table and columns you want to update, you have to tell SQL Server which rows you’re interested in updating. This introduces the WHERE clause to the T-SQL statements you’re learning. The WHERE clause is used in DELETE and SELECT statements, as well. You can choose to leave the WHERE clause off, but then you’ll be updating all values in the table.
The semantic web is the next level of web searching, where data is more important and should be well-defined. The semantic web is needed for making web searches more intelligent and intuitive to user requirements. You can find some interesting points on the semantic web here.
Triples are an atomic entity in RDF. They're composed of subject-predicate-object and used for linking the subject and object with the help of the predicate. You can find some interesting points on triples here.
One of the coolest features in the RC2 release for RavenDB is the automatic setup — in particular, how we managed to get a completely automated, secured setup with a minimal amount of fuss on the user’s end.
You can watch the whole thing from start to finish — it takes about three minutes to go through the process (if you aren’t also explaining what you are doing) and you have a fully secured cluster talking to each other over secured TLS 1.2 channels. This was made harder because we are actually running with trusted certificates. This was a hard requirement because we use the RavenDB Studio to manage the server, and that is a web application hosted on RavenDB itself. As such, it is subject to all the usual rules of browser-based applications, including scary warnings and inability to act if the certificate isn’t valid and trusted.
Distributed transactions are one of the meanest, baddest problems in relational databases. With the release of Citus 7.1, distributed transactions are now available to all our users. In this article, we are going to describe how we built distributed transaction support into Citus by using PostgreSQL modules. But first, let's give an overview of what a distributed transaction is.
(If this sounds familiar, that's because we first announced distributed transactions as part of the Citus Cloud 2 announcement. The Citus Cloud announcement centered on other new useful capabilities, such as our warp feature to streamline migrations from single-node Postgres deployments to Citus Cloud, but it seems worthwhile to dedicate an entire post to distributed transactions.)
In this blog post, we'll look at some of the facets of InnoDB page compression.
Somebody recently asked me about the best way to handle JSON data compression in MySQL. I took a quick look at InnoDB page compression and wanted to share my findings.
Think about the power that database administrators have in your organization's world. I’ve been working with databases since my first job in 1987. I’ve seen the power bestowed upon database administrators in organization after organization. They are fully aware of the power they control, and most other people in an organization are regularly reminded of this power. The defensive database administrator is always the biggest obstacle in the way of API teams who are often seen as a threat to the power and budgets that database groups command. This power is why databases are often centralized, are scaled vertically, and are the backends to so many web, mobile, desktop, and server applications.
I spend a significant amount time thinking about the power that database administrators wield and how we can work to find more constructive, secure, and sensible approaches to shifting legacy database behaviors. Lately, I also find myself thinking a lot more about blockchain — not because I’m a believer but because so many believers are pushing it onto my radar. Blockchain will continue to be a thing, not because it is a thing, but because so many people believe it is a thing. Most blockchains will not withstand the test of time — they are vapor — but the blockchains that remain will do so because people have convinced other people to put something meaningful into their blockchain, much like we have convinced so many companies, organizations, institutions, and government agencies to put data into databases.
GraphQL burst into developer’s public sphere in 2015 and in two short years, the data query language from Facebook that sought to create an alternative to REST APIs gained a massive amount of popularity. My experiments found it promising and interesting, but it was confusing to understand the steps to production and it was lacking in certain tooling.
I had encountered GraphCool around Berlin, as they organize and sponsor the community meetup, and I interviewed their CEO Johannes Schickling about what problem the company intended to solve and how.
Welcome back! In our last Database deep dive, we talked about NoSQL and all the things you need to know about it, such as the biggest challenges of moving to NoSQL and jobs for the SQL expert. These are two of the many major items of interest to database administrators. That's why this time around, we're talking to the database administrators in the audience (can I get a what what?!) about what it takes to be a DBA, listing jobs DBAs may be interested in, providing the most recent news in the DBA world, and more. Let's get started!
Database Administration on DZoneCheck out some of the top DBA-related articles on DZone. You'll undoubtedly find something here of interest to you, whether you're an Agile aficionado, about to transition to a different kind of database administration, or want to know what the future holds for DBAs.
In this blog post, we'll look at some common MongoDB topologies used in database deployments.
The question of the best architecture for MongoDB will arise in your conversations between developers and architects. In this blog, we wanted to go over the main sharded and unsharded designs, with their pros and cons.
In this blog post, I'll look at MySQL and Linux context switches and what is the normal number per second for a database environment.
You might have heard many times about the importance of looking at the number of context switches to indicate if MySQL is suffering from the internal contention issues. I often get questions about what is a "normal" or "acceptable" number, and at what point you should worry about the number of context switches per second.
Since the purpose of a database system is to store data, there is a close relationship with the filesystem. As MySQL consultants, we always look at the filesystems for performance tuning opportunities. The most common choices in term of filesystems are XFS and EXT4; on Linux, it is exceptional to encounter another filesystem. Both XFS and EXT4 have pros and cons, but their behaviors are well-known and they perform well. They perform well but they are not without shortcomings.
Over the years, we have developed a bunch of tools and techniques to overcome these shortcomings. For example, since they don't allow a consistent view of the filesystem, we wrote tools like Xtrabackup to backup a live MySQL database. Another example is the InnoDB double write buffer. The InnoDB double write buffer is required only because neither XFS nor EXT4 is transactional. There is one filesystem which offers nearly all the features we need, ZFS. ZFS is arguably the most advanced filesystem available on Linux. Maybe it is time to reconsider the use of ZFS with MySQL.
With Redis Enterprise, we recently enabled the ability to extend your RAM-based storage into Flash memory. Don't confuse this with some form of persistence — this is a way to let Redis break out of the bounds of the server RAM and into Flash storage as needed. With the advances in Flash memory (NVMe-based SSD storage), the performance becomes very viable, although not quite as quick as RAM alone. This allows you to have hybrid storage in which data moves between fast RAM and Flash as needed, all managed by Redis Enterprise and without changes to your code.
Let's take a look at the performance characteristics of Redis Enterprise on Flash and how you can test the performance yourself. We suggest installing Redis Enterprise directly as described in our documentation. While we offer instructions on how to use Docker to install Redis Enterprise to test out the product, in this case, that method will not yield the highest performance.
Even the most technically minded companies need to think about design. Working on a database product at a startup is no different. But this comes with challenges, such as figuring out how to implement human-centered design methodology at a technical company but also how to contribute to building a design process that everyone agrees with across the organization. This blog will detail how product design is done at MemSQL as well as highlight how to design enterprise products at a startup.
How Do We Define Product Design?Product design is the end-to-end process of gathering requests and ideating in order to hand off pixel-perfect products and iterations. There are usually two different ways of dividing work: breaking down multiple design tasks into steps handled by different team members, or each designer taking ownership of a product, or a feature, and designing in a full-stack way. At MemSQL, we develop each product with the latter model, which requires constant and proactive engagement with other folks on the team.
In this blog series, we’ll be experimenting with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern data lakes, open-source DevOps on the cloud with protected internal legacy tools, SQL with NoSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT sensor data with idle chatting, we’re curious to find out: will they blend? Want to find out what happens when IBM Watson meets Google News, Hadoop Hive meets Excel, R meets Python, or MS Word meets MongoDB?
Follow us here and send us your ideas for the next data blending challenge you’d like to see.
MariaDB® Corporation has introduced new product enhancements to MariaDB AX to deliver a modern approach to data warehousing that enables customers to perform fast and scalable analytics more cost-effectively. MariaDB AX expands the MariaDB Server, creating a solution that enables high-performance analytics with distributed storage and parallel processing and scales with existing commodity hardware on premises or across any cloud platform.
“MariaDB AX is a powerful, open-source solution for performing custom and complex analytics,” says David Thompson, VP of Engineering at MariaDB Corporation. “In order to fully realize the power of big data, our customers need the ability to gather insights in near-real-time, regardless of where the data is coming from. With MariaDB AX, it’s easier than ever to ingest and analyze streaming data from disparate sources, while ensuring the highest level of reliability through new high availability and backup capabilities.”Data warehouses are traditionally expensive and complex to operate. Driven by the need for more meaningful and timely analytics that meet hardware and cost pressures, companies are reassessing their data warehouse and analytics strategy. Built for performance and scalability, MariaDB AX uses a distributed and columnar open-source storage engine with parallel query processing that allows customers to store more data and analyze it faster. MariaDB AX supports a wide range of advanced analytic use cases across every industry; for example, identifying health trends to inform healthcare programs and policy, behavioral analysis to inform customer service and sales strategies, and analysis of financial anomalies to inform fraud programs.
Global secondary indexes in Couchbase can be created, updated, and deleted without impacting the reads and writes on the JSON documents in data nodes. This means that index inserts/updates/deletes happen asynchronously, and index workloads are isolated from the rest of the system.
Indexes are directly related to the N1QL queries that are run. N1QL and GSI tango together. Indexes are to be created with N1QL queries in mind, as indexes are meant to be steroids for queries, to reduce the query latency costs, and to increase throughput. Indexes also demand their own storage, but the risk of losing business due to slow/shoddy customer engagement experience is higher than the associated cost of having indexes. Also, indexes in most cases live outside the confines of an application, which helps in managing the lifecycle of indexes suitably.
AWS Glue is an Extract, Transform, Load (ETL) service available as part of Amazon's hosted web services. Glue is intended to make it easy for users to connect their data in a variety of data stores, edit and clean the data as needed, and load the data into an AWS-provisioned store for a unified view.
Glue supports accessing data via JDBC, and currently, the databases supported through JDBC are Postgres, MySQL, Redshift, and Aurora. Of course, JDBC drivers exist for many other databases besides these four. Using the DataDirect JDBC connectors, you can access many other data sources for use in AWS Glue.
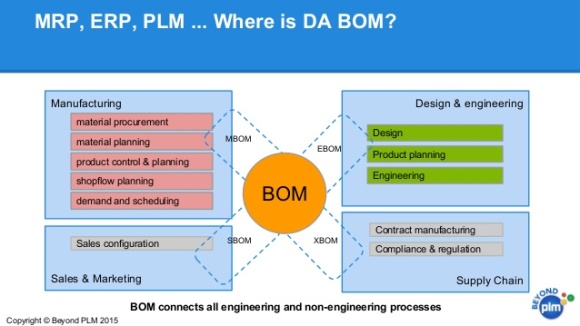
Where is da BOM? the above question asks, and the obvious answer is right in the middle of your organization, nestled between manufacturing, design, sales, and supply chain. But I have a better answer. Your Bill of Materials should be in Neo4j. Today, I'll show you why.
Let's start with a simple example first by creating a BOM in Neo4j.
You've no doubt heard at least something about the GDPR, the EU's new privacy and data management law, with its greatly increased maximum fines for noncompliance and tighter definitions for acceptable uses of personal information.
If you've continued reading past paragraph one of any of the many articles, you'll be aware that the law applies globally to all organizations holding EU citizens' data — it's not bounded by geography or jurisdiction.
The sudden increase in the volume of data from an order of gigabytes to zettabytes has created the need for a more organized file system for storing and processing data. The demand stemming from the data market has brought Hadoop into the limelight, making it one of biggest players in the industry. Hadoop Distributed File System (HDFS) — the commonly known file system of Hadoop — and HBase — Hadoop’s database — are the most topical and advanced data storage and management systems available in the market.
What Are HDFS and HBase?HDFS is fault-tolerant by design and supports rapid data transfers between nodes — even during system failures. HBase is a non-relational and open-source NoSQL database that runs on top of Hadoop. HBase falls under the CP type of the CAP (consistency, availability, and partition tolerance) theorem.

Modernizing your existing apps and building out new, real-time apps can be an overwhelming process. Keeping up with user response times is only one piece of the puzzle that developers today must solve. Today's developer faces a number of challenges when building great software.
The modern application needs to cater to a variety of functions and services. They need to accomplish both transactions, analytics, operational processing, and so on. Often, they deal with a wide variety of data — from location to relationships to documents or graph. They can be legacy or brand new developments in a variety of popular languages and stacks. They have to be fully elastic while scaling and have the ability to be deployed in a multitude of environments — whether that be on-premises, cloud, PaaS, or hybrid. But in all cases, they need to meet time-to-market requirements and stay within corporate budgets.
A couple of years ago, we moved our code base to a monorepo, which helped us scale tremendously in terms of code reuse and overall speed of development. We are extremely proud of our ability to run a resilient service that has 99.99% availability with zero downtime upgrades.
From the beginning of this journey, I made a decision to go all-in on JavaScript as our default coding language. The most important reason for this was that I wanted to hire full-stack developers who could work on every aspect of the product, so we chose Angular.js for UI, Node.js for API, and a schema-less JSON database (NoSQL MongoDB). We made all technology decisions based on this one philosophy (another blog coming about what I learned and why I am no longer a fan of full-stack development) and it worked beautifully...for a while.
In this article, I will show you how to connect a MySQL database with your Spring Boot application.
All the code is available on GitHub!
In this article, I’ll explain how to create a foreign key on a table in Oracle SQL.
What Is a Foreign Key?First, let’s explain what a foreign key is.
Today, Redis applications can take advantage of a few types of replication:
LAN-based replication: Tuned for LAN characteristics; low latency and high bandwidth networks with only a few retransmissions. WAN-based replication: Tuned for WAN characteristics; high latency and low bandwidth networks with high network "noise" ratio.In the upcoming version of Redis Enterprise 5.0, we are delivering a new flexible, multi master replication technology built for WAN. The new capability allows active-active geo-distributed Redis deployments using the magic of CRDTs (conflict-free replicated data types). CRDTs simplify development of active-active systems and automatically resolve conflicting writes. Combined with Redis datatypes, CRDTs provide a mechanism that can easily help you develop active-active geo-distributed systems that can intelligently handle conflicting writes.
There may come a time when you are using JdbcTemplate and want to use a PreparedStatement for a batch update. In the example below, we will explore how to insert thousands of records into a MySQL database using batchUpdate.
First, we must configure the datasource to use in our application.properties.
As part of our work on the Neo4j Developer Relations team, we are interested in integrating Neo4j with other technologies and frameworks, ensuring that developers can always use Neo4j with their favorite technologies.
One of the technologies that we’ve seen gain a lot of traction over the last year or so is Kubernetes, an open-source system for automating deployment, scaling and management of containerized applications.
 It has been two months since the first release candidate of RavenDB 4.0, and the team has been hard at work. Looking at the issues resolved in that time frame, there are over 500 of them, and I couldn’t be happier with the result.
It has been two months since the first release candidate of RavenDB 4.0, and the team has been hard at work. Looking at the issues resolved in that time frame, there are over 500 of them, and I couldn’t be happier with the result.
RavenDB 4.0 RC2 is out now! Get it here (for Windows, Linux, OSX, Raspberry PI, and Docker).
The biggest online shopping days of the year are just around the corner. Is your database ready? By tuning 20 key MariaDB system variables, you'll bolster your database's performance, scalability, and availability, ensuring every potential customer has a smooth user experience. The following system variables come up repeatedly in configuring an optimal MariaDB server environment. Implement our recommendations for the most tuned values, and make this year's Black Friday through Cyber Monday period your best ever.
A couple of important notes:
The Devart company recently released UniDAC with support for Linux 64-bit platform. UniDAC makes application development and maintenance easier and simpler because the use of Direct mode in a custom application does not require the installation of client libraries, additional drivers, etc. This helps to avoid the overhead when accessing a DBMS, hence increasing performance.
So, in this article, we will demonstrate the capability of UniDAC to establish a connection to various DBMSs in Direct mode:
How do you build your own Tarantool application without overcomplicating things? This second tutorial will cover networking as well as installing and using third-party Tarantool packages.
If you missed Part 1, you can find it here.
Database row-locking is one of the great features provided by RDBMS vendors to manage synchronization of concurrent data processing activities on a given table. Although it’s a great feature, it can lead to critical scenarios like your system being stuck due to stale locks on the database side.
In this blog post, I’m going to explain how to use Spring JDBC with the row-locking feature of Oracle database to maintain the synchronization of concurrent data processing tasks that are expected to transform some data and persist it back to the database.
Thanks to Ravi Mayuram, S.V.P. Engineering and CTO at Couchbase, for sharing his insights on the current and future state of databases. Ravi has been with Couchbase for four and a half years after being with Oracle and Siebel.
Q: What are the keys to a successful database strategy?
PL/SQL is, in almost all ways, a straightforward and deceptively simple programming language. The "deception" lies in how simplicity can sometimes mask capability. It is easy to learn the basics of PL/SQL, and you can become productive very quickly. And then you also quickly see how powerful and capable is PL/SQL.
So I offer another post on PL/SQL fundamentals, this one offering key points to remember when declaring constants and variables.
Time-to-value is often mentioned with great emphasis in marketing brochures but is rarely explained in detail. Perhaps the marketing mavens believe that the idea explains itself. After all, buying a product or service and being able to use it immediately — a time-to-value of zero — is instant gratification.
 However, time to value is usually somewhat greater than zero. Here's a simple example. You buy a cabinet from IKEA to put your china in. You need to get it home and assemble it. Perhaps it will take half a day to complete that and dispose of the packaging. Or perhaps you'll get the assembly wrong (it happens) and you'll have to hire some help to sort it out. So, the time to value could be a day or more, but that's still fairly fast.
However, time to value is usually somewhat greater than zero. Here's a simple example. You buy a cabinet from IKEA to put your china in. You need to get it home and assemble it. Perhaps it will take half a day to complete that and dispose of the packaging. Or perhaps you'll get the assembly wrong (it happens) and you'll have to hire some help to sort it out. So, the time to value could be a day or more, but that's still fairly fast.
In this blog post, I'll discuss how NoSQL data modeling is different from traditional relational schema data modeling, and I'll also provide you with some guidelines for document database data modeling.
Document databases, such as MapR-DB, are sometimes called "schema-less" — but this is a misnomer. Document databases don't require the same predefined structure as a relational database, but you do have to define the facets of how you plan to organize your data. Typically, with a NoSQL data store, you want to aggregate your data so that the data can quickly be read together, instead of using joins. A properly designed data model can make all the difference in how your application performs. We have an anecdote at MapR where one of our solution architects worked with a customer, and in a one-hour conversation about schema design, was able to improve access performance by a factor of 1,000x. These concepts matter.
In this article, I will share my experiences creating applications for Tarantool. The whole series will cover an existing Tarantool application, and this individual tutorial will touch upon installing Tarantool, storing and accessing data, and writing stored procedures.
Tarantool is a NoSQL/NewSQL database that stores data primarily in RAM but can also use disk and ensures persistence via a well-designed mechanism called a “write-ahead log” (WAL). Tarantool also boasts a built-in LuaJIT (just-in-time) compiler that allows the execution of Lua code.
How do you create a database for testing that is like your production database? It depends on how you want the test database to be "like" the production one.
Replacing Sensitive DataCompanies often use an old version of their production database for testing. But what if the production database has sensitive information that software developers and testers should not have access to?
Apache Ignite is a relatively new solution, but its popularity is quickly increasing. It is hard to assign to a single area of database engine division because it has characteristics typical for some of them. The primary purpose of this solution is an in-memory data grid and key-value storage. It also has some common RDBMS features like support for SQL queries and ACID transactions. But that’s not to say it is a full SQL and transactional database. It does not support foreign key constraints, and transactions are available only at the key-value level. Despite this, Apache Ignite seems to be a very interesting solution.
Apache Ignite may be easily started as a node embedded to Spring Boot application. The simplest way to achieve that is by using the Spring Data Ignite library. Apache Ignite implements a Spring Data CrudRepository interface that supports basic CRUD operations and also provides access to the Apache Ignite SQL Grid using the unified Spring Data interfaces. Although it has support for distributed, ACID, and SQL-compliant disk store persistence, we designed a solution that stores in-memory cache objects in a MySQL database. The architecture of the presented solution is visible in the figure below and as you can see, it is very simple. The application put data to the in-memory cache on Apache Ignite. Apache Ignite automatically synchronizes this changes with the database in an asynchronous, background task. The way of reading data by an application also should not surprise you. If an entity is not cached, it is read from the database and put to the cache for a future use.
DZone Database Zone Fun With SQL: Functions in Postgres In our previous Fun with SQL post on the Citus Data blog, we covered w...

